
In the previous post, we broke down the monolith into coarse-grained Microservices based on their business domain purpose, which changed our architecture style from monolith to service-based. We refrained from migrating to Microservices right after and decided to wait a little before taking the next round. Now, as our application is stable and running smoothly, we are ready to take it further. So, without further delay, let’s get started.
Table of Contents
What is Microservice
Before we begin migration to Microservices, we need to clearly understand what a Microservice is. What does it take to make a service micro? What are the characteristics of Microservices?
Micro is small. But how small, how many lines of code? This is not about lines of code, it’s about responsibilities. How many things is the service responsible for? A microservice does one thing, but it does it well. Speaking in Domain-Driven Design terms, I would keep a microservice responsible for a scope as large as a bounded context and as small as an aggregate.
Microservice is an independent unit of development. Each microservice can be developed completely independently, as long as we have agreed upon an API. For each microservice, we have an option to select a programming language and a framework that is the “best tool for the job”. We are not bound to a single choice for an entire system. One programming language may be a good fit for implementing one part of a system, but a terrible choice for the other.
Microservice is an independent unit of deployment. We can deploy a single microservice at any point in time without considering the rest of the system. Deployment of each microservice is independently reversible, if needed.
Microservice is an independent unit of scale. One part of a system may have to process more requests than the other, or even encounter different load patterns based on time of the day, day of the week, etc. We can run more or less instances of a microservice based on expected or current load. That allows us to fine-tune the balance between performance and cost of infrastructure. The difference can be significant, especially if running on a cloud infrastructure, e.g. AWS.
Microservice functionality is available through API and API only. No other part of the system can access or directly manipulate the data microservice owns.
As we can see, microservices are quite autonomous creatures: they have an API as a single point of contact and source of creating dependencies, are responsible for one thing, have ownership of data, can be implemented, deployed, and scaled independently.
How to get ready for Microservices
We definitely need rollout and rollback strategies. We can put in place proxies to redirect clients of the APIs we migrate to old or new implementations, gradually or all at once. Anything we deploy, we should be able to roll back immediately.
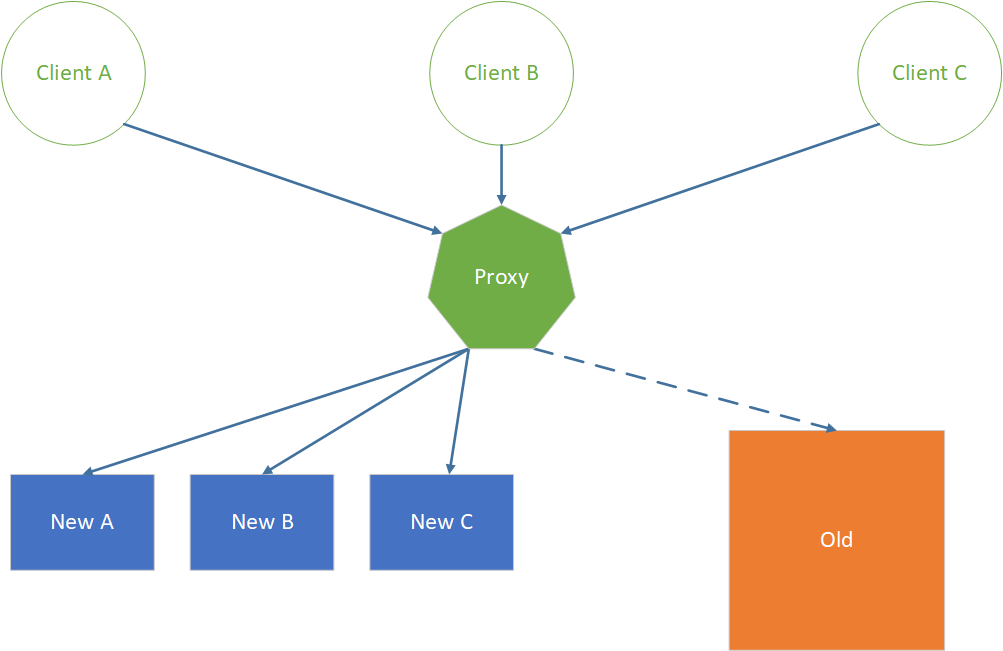
Various deployment strategies can help too. For example, one of the techniques is blue-green deployments. With this technique, we have two parallel production environments. One is active and serves clients, and the other holds the previous release. If we need to roll back, we just switch the proxy to route clients back to the previous release. To deploy a new version, we push changes to the inactive environment and then switch clients’ requests to hit the new version.
Another approach is canary deployments. With this approach, instead of rolling new functionality to all users, we can verify a change in the production environment by routing only a subset of users to the new functionality. Once we are sure that the new functionality works, we switch the rest of the clients to use it.
As the number of microservices grows, the need for automation emerges. Managing the deployment of hundreds or thousands of independent bits is very complex and error-prone. Continuous Integration and Continuous Delivery (CI / CD) come to the rescue. CI / CD can automatically check the quality of code, verify behavior by running automated tests, package code, and deploy a microservice to production.
We also need service discoverability. When one microservice needs to talk to the other, it should have a way to find the address of the other service, e.g. look up IP address and port by some alias name. Or maybe, we run our microservices in Kubernetes, that among the rest will give us service discovery.
We definitely need observability, that includes logs, metrics, and alarms. With a large number of services running, we need tools that provide us with a coherent view of our system health. We need automated notifications if anything goes wrong and the ability to trace a problem back to an instance of a running microservice.
Teams need to be comfortable with all the tools and techniques in order to work effectively with microservices; therefore, it will take some time to transition to this mode of operation. Start migration slowly. We need to learn to walk before we can run. Think about choosing the part of the system that can teach you the most about the process and has low impact if we make a mistake.
What is the first pick?
Now we are ready to start working on migration. If we take our service-based architecture as an example, where do we start first?
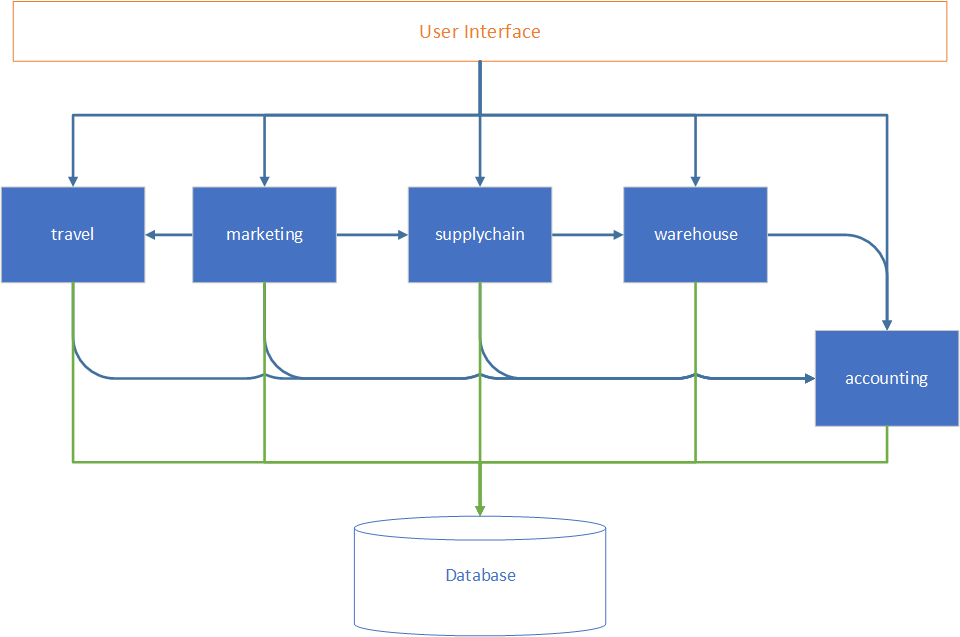
There are two orthogonal forces that impact your decision:
- One pulls toward the easiest to migrate and less impactful component.
- Second pull toward the component that will benefit the most from migration.
We map our Macroservices to the chart to arrange them based on simplicity and importance of migration. The best bet for us is to select important and simple ones that correspond to the upper-right corner.
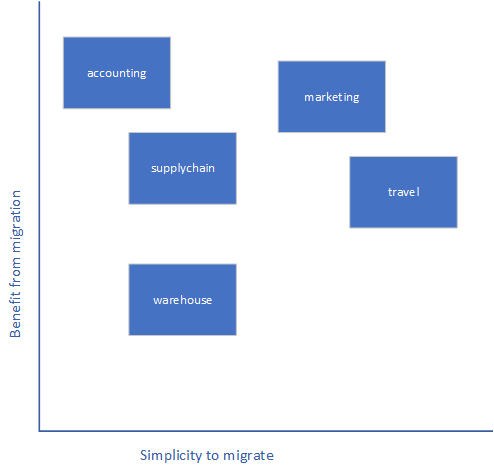
Based on our chart, there are two good candidates for migration: marketing and travel services. Travel services are a bit simpler to migrate, but users will get more benefits from marketing service migration. So, marketing services, let it happen!
The steps
Now let’s take marketing service and walk through migration steps together. While looking closely at the service, we can identify four main themes it’s responsible for: leads, messaging, tracking, and campaigns.
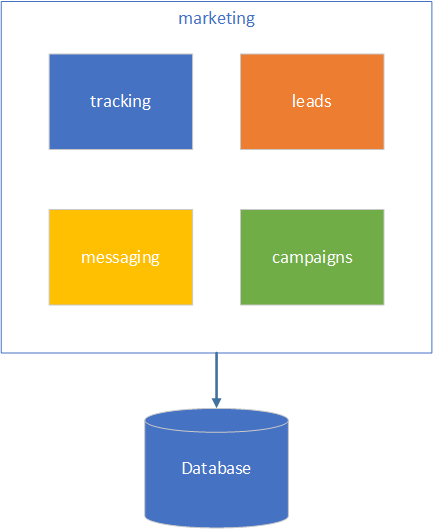
These themes can be our four coarse-grained services to start with. Even though they use the same database and share tables, we have made our first step by splitting a large marketing service into coarse-grained services based on functionality.
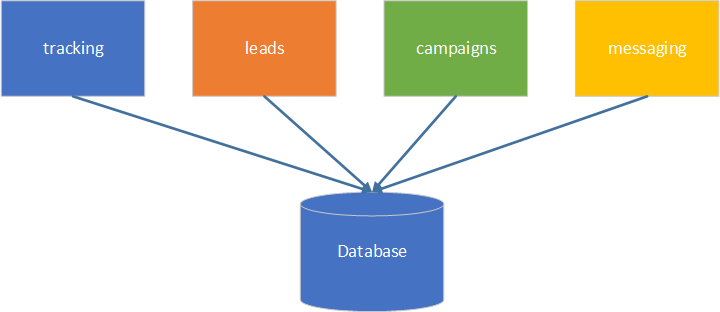
Now it’s time to eliminate coupling based on data. So, let’s see how our services map to data tables (in case of a relational database).
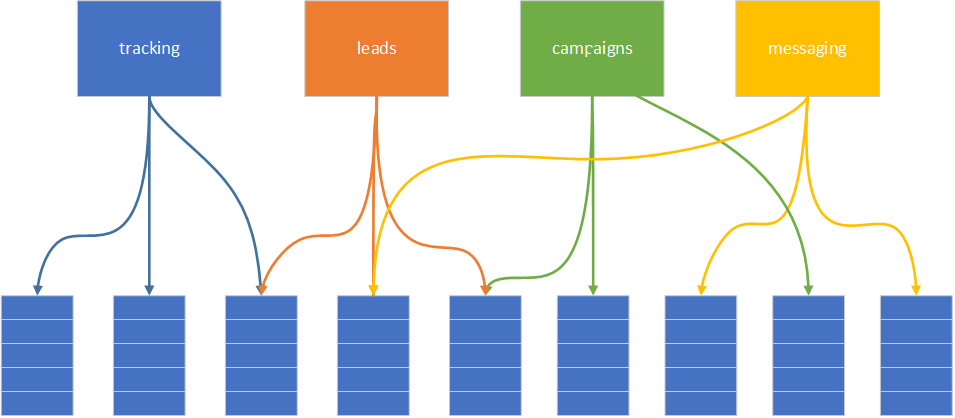
Because we have a shared database, we have some tables shared between different services. Luckily, the other tables are not shared, so we can easily split coarse-grained services based on the data being mapped as shown below.
As a result, we have tracking ads microservice separated. Great!
Next step is to take care of the tracking leads service. It shares data with the leads service, so it is not so trivial, but we have a couple of options. Take a closer look at the shared table to see whether it belongs to the leads or tracking leads service. If it’s neither, find a way to split the data amongst these two. In our case, we decided that the data ownership belongs to the leads service; therefore, the tracking leads service should stop accessing data directly and instead use the leads service interface.
We have one more check to do. If tracking leads and leads services are too chatty, that is an indicator of too tight coupling. We need to go back to refine services’ granularity and do one more iteration of splitting based on data.
Since we have tracking as a subsystem, we may find ourselves in a situation where managing interaction with tracking is difficult for our clients. In this case, we need to introduce an orchestration layer for the tracking system. Orchestration could be just another service that communicates with a cluster of tracking services and provides clean and easy-to-use APIs.
Don’t forget that we got to deploy to production and route real traffic to our new tracking system. If possible, you may consider deploying to production more often, even some intermediary results. Note that deployment to production and routing real traffic to new services are two separate tasks. You may exercise production deployment to get confidence in this process and not yet route real traffic to new services. However, the sooner you get real traffic hitting new services, the earlier you can get feedback and the cheaper it would be to change the course of action if any mistakes are revealed.
Reflect and repeat. Work through the other services, first splitting them into coarse-grained services based on functionality, then mapping services to data and splitting further by data ownership. If there is any shared data identified, decide on data ownership. Each service is responsible for its data; others can access the data through the service API. Next, check for tight coupling between services, refine by functionality and data again if tight coupling is present. Finally, think about the orchestration level. Rinse and repeat until the goals and objectives of migration are achieved.
Summary
Microservices is not “the” architecture; it’s one of the available architectures (along with monolith and service-based) to choose from. Microservices migration has to be driven and justified by business value. The microservices approach requires people, processes, and tools to be ready to operate in such an environment; that doesn’t happen overnight. Migration is an iterative process that benefits from incremental releases to production.
If you need to deep-dive into the subject, learn more about migration approaches and patterns. Below is a list of books that you will find very helpful. Good luck on your migration journey!
Reading List
 | Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith, by Sam Newman. |
 | Building Event-Driven Microservices: Leveraging Distributed Large-Scale Data, by Adam Bellemare. |
 | Design & Build Great Web APIs, by Mike Amundsen. |


One thought on “Migrating Monolith to Microservice Architecture – Journey Continues”