
Kafka or RabbitMQ? If you are looking for a concise yet complete answer on any of the following questions, this post aims to provide you enough information to decide: what is better Kafka or RabbitMQ; how Kafka and RabbitMQ are different; when should you choose one over the other.
Similarities
Both Kafka and RabbitMQ provide
- Asynchronous messaging middleware;
- Publisher-subscriber model implementation;
- Fanout of messages;
- At-least once delivery;
- Queues / Topics replication;
- Both are highly scalable and highly available systems;
- And etc.
Both systems have been used by commercial organizations for a long time, therefore Kafka and RabbitMQ are both stable and production ready. There are client libraries and packages for most of popular programming languages that are well supported and also stable.
Though there are quite a lot high level similarities between, however Kafka and RabbitMQ take different implementation approaches and therefore they specialize on solving different problems. Each has its own strengths and weaknesses and the choice will mostly likely depend on your circumstances.
To make an informative decision it’s important to understand how Kafka and RabbitMQ work internally, therefore let’s take a look at simplified architectures of each of them first.
Architecture
Kafka
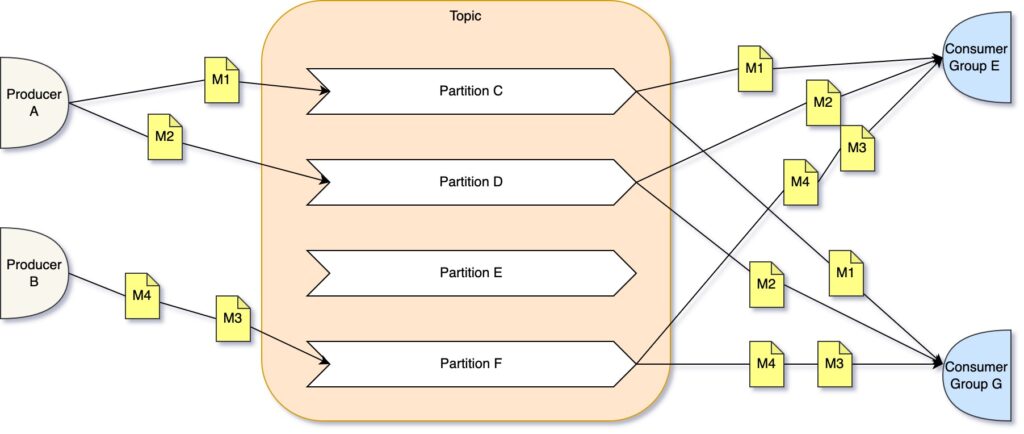
Kafka isolates messages in topics. Each topic is comprised of partitions. Partition is a method of scaling where messages can be read from all partitions concurrently. For example, if you configure Kafka to have 5 partitions you may have 5 client instances reading messages from the same topic on all 5 partitions all at the same time.
When producer puts a message in a topic the message is placed in one of the partitions based on a partition key, each message has one. Messages with same partition key are guaranteed to be placed in the same partition in exact order they arrived, therefore order of messages read is guaranteed, but only withing a partition. Order of messages that are read from different partitions is not guaranteed, because messages are read concurrently and therefore different client instances may read messages with different pace.

Messages that are read from Kafka topic remain in the topic until they are deleted. You can configure message deletion policy based on your requirements. Each client remembers last read message offset and essentially moves the offset after reading new message. This property allows clients to replay messages that are still available in a topic in case of failure.
Message fanout is achieved by using consumer groups. Each consumer group reads a copy of a message from a topic. For example, given you have 3 consumers and each requires to receive all messages. The way to implement it with Kafka is to assign each consumer its own group. Each consumer may have multiple instances and all instances of the same consumer belong to the same consumer group.
Personally, the way I think about Kafka is a transaction log, where each message is recorded and clients may read and re-read messages at any point in time as long as messages are not deleted.
RabbitMQ
Let’s switch gears and look at RabbitMQ simplified architecture. RabbitMQ implements AMQP protocol.
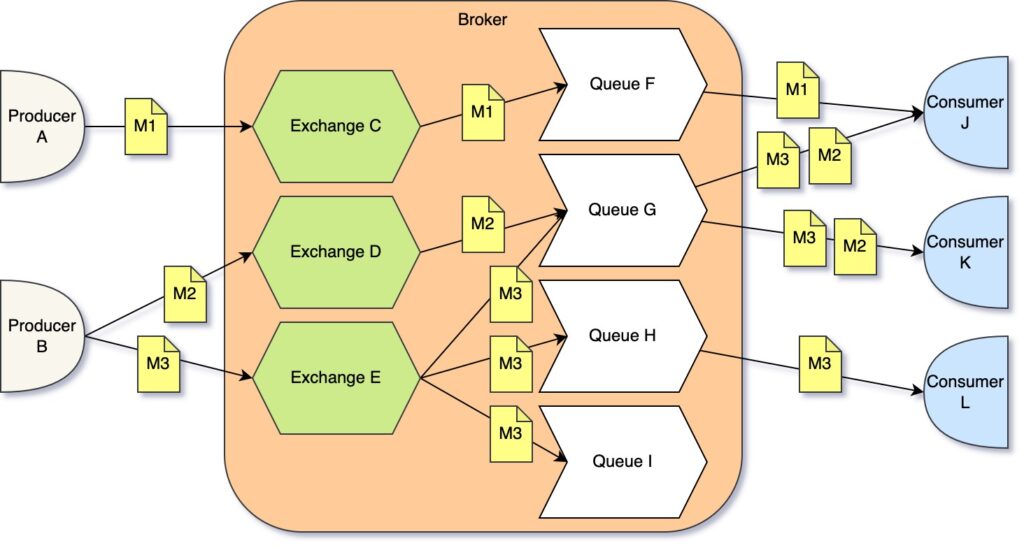
Producer and consumer both connect to a broker. Broker “hosts” exchanges. Producer sends messages to an exchange. Exchange may have zero, one or multiple queues bound to it.
Consumers subscribe to existing queues or create new queues if they don’t exist. Exchanges route messages to a single or multiple queues based on a routing key. If exchange has multiple queues that match a message routing key, RabbitMQ will copy the messages to each matching queue. There are different types of RabbitMQ exchanges; exchange type defines how messages are routed. We are not going to dive into the topic of exchanges in this post; what is important to understand for now is that RabbitMQ takes care of messages routing itself.
Queues can be durable or no-durable. Durable queues survive RabbitMQ restart, while non-durable queues not; therefore, messages can be lost in non-durable queues.
Messages are deleted from queues after they are consumed. Therefore, consumed messages cannot be replayed or consumed again.
Message fanout is achieved by using a fanout exchange. This type of exchange will replicate all messages to all queues. Repeating same example where we have 3 consumers and each requires to receive a copy of each message. With RabbitMQ we will use a fanout exchange and each consumer will create its own queue. RabbitMQ fanout exchange will take care of message replication to each queue.
I personally consider using RabbitMQ when architecture demands extensive message routing. RabbitMQ is message routing machine that allows producers as well as consumers to declare elaborate topologies using different types of exchanges, queues and filters.
Choose one!
A comparison table below is designed to help you choose between Kafka and RabbitMQ and decide which one fits your architecture best.
<<COMPARISON TABLE>>
| Kafka | RabbitMQ | |
|---|---|---|
| How messages are delivered? | Messages are pulled from a topic by clients. | Messages are pushed from a queue to subscribed client or clients. |
| What is message lifecycle? | Messages remain in a topic for as long as retention policy allows. | Messsages are deleted from a queue as soon as they are consumet by clients. |
| Can messages be replayed? | Yes | No |
| Is message fanout supported? | Yes, using consumer groups. | Yes, using fanout exchcanges. |
| Is message routing supported? | None, messages are stored in topics that receive them. | Yes, and quite elaborate with exchanges, queues and filters. |
| How messages are isolocated? | By topics. | By queues. |
| What are message ordering guarantees? | FIFO Ordering Is guaranteed withing a partition. | FIFO Ordering is guaranteed withing a queue with a single consumer. |
| Is there any control over message priority? | No | Yes, with priority queues. |
| Is message filtering supported? | No | Yes, messages have routing keys whixh can be also be used as filter criteria. |
| What is expected throuhgoutput? | Extremily high. No overhead for exchanges and routing. | Decent, will fot most of applications. |
Summary
Hope this post was useful and helped you to decide which messaging middleware to select. In case of Kafka and RabbitMQ it is not possible to pick one without knowing a context. Both are solid tools and work great to solve problems there were designed for to solve.
If you find anything is missing in the post, please leave a comment, and happy coding!